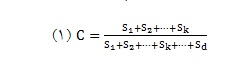نوع مطالعه: پژوهشي |
موضوع مقاله: ژنتيك انتشار: 1394/10/15
متن کامل: (6398 مشاهده)
تشخیص لوسمی لنفوسیتی و میلوئیدی حاد با استفاده از انتخاب ژن دادههای ریزآرایه و الگوریتمهای داده کاوی
راضیه شیخپور1، مهدی آقاصرام2، رباب شیخپور3
چکیده سابقه و هدف تکنولوژی ریزآرایه، یکتصویر کلیازمیزانبیانهزاران ژن به طور هم زمانارایه میدهد. تفسیر دادههای ریز آرایه بدون آنالیز آماری و روشهای هوش مصنوعی ممکن نیست. هدف این مقاله، تشخیص انواع لوسمی حاد با استفاده از مجموعه دادههای ریز آرایه و الگوریتمهای داده کاوی بود. مواد و روشها در این مطالعه توصیفی از دادههای بیان 7129 ژن مربوط به 72 بیمار مبتلا به لوسمی استفاده شد. سپس با انتخاب ژنهای مهم بر اساس روشهای ضریب همبستگی، بهره اطلاعاتی، نسبت بهره و امتیاز Fisher و با استفاده از روشهای جداکننده خطی، ماشینبردار پشتیبان، k نزدیکترین همسایه، بیزینساده، شبکه بیزین، نزدیکترین میانگین، رگرسیون لجستیک، شبکه عصبی پرسپترون چند لایه و درخت تصمیم J48 برروی ژنهای انتخاب شده به تشخیص لوسمی میلوژنیکو لنفوسیتیک حاد پرداخته شد. یافتهها روشهای نزدیکترین میانگین، ماشینبردار پشتیبان، k نزدیکترین همسایه، بیزین ساده و شبکه عصبی پرسپترون چند لایه با استفاده از 39 ژن انتخاب شده توسط نسبت بهره با دقت 100٪ ، قادر به تشخیص لوسمی میلوژنیکو لنفوسیتیک حاد هستند. هم چنین روش ماشینبردار پشتیبان با استفاده از 87 ژن انتخاب شده توسط بهره اطلاعاتی و روش شبکه عصبی پرسپترون چند لایه با استفاده از 133 ژن انتخاب شده توسط بهره اطلاعاتی با دقت 100٪ ، قادر به تشخیص آن میباشند. نتیجه گیری نتایج این مطالعه نشان داد که انتخاب ژنها و الگوریتمهای داده کاوی قادر به تشخیص انواع لوسمی با دقت بسیار بالایی هستند، بنابراین با استفاده از این روشها، میتوان تصمیمات مناسبی در مورد نحوه تشخیص و درمان بیماران گرفت. کلمات کلیدی:لوسمی لنفوسیتیک حاد، لوسمی میلوژنیک حاد، آنالیز ریز آرایه، داده کاوی
تاریخ دریافت : 17/10/93 تاریخ پذیرش : 21/4 /94
1- دانشجوی دکترای کامپیوتر ـ دانشکده مهندسی برق و کامپیوتر ـ دانشگاه یزد ـ یزد ـ ایران 2- دکترای تخصصی کنترل سیستمها ـ دانشیار دانشکده مهندسی برق و کامپیوتر ـ دانشگاه یزد ـ یزد ـ ایران 3- مؤلف مسئول: PhD بیوشیمی ـ دانشکده پزشکی، واحد یزد، دانشگاه آزاد اسلامی و مرکز تحقیقات خون و انکولوژی، دانشگاه علوم پزشکی شهید صدوقی، یزد، ایران، صندوق پستی: 56965-89156
مقدمه سرطان بعد از بیماریهای قلبی ـ عروقی، دومین علت اصلی مرگ و میر در جهان میباشد. سرطانیکبیماری ژنتیکیاست کهدر نهایتزاییدهاثرات عواملمحیطی است(2، 1). اگرسرطانهادرمراحلاولتشخیصداده شوند، قابلمعالجههستند(3). سرطانخون یا لوسمی؛ بیماری پیشرونده و بدخیماعضای خون ساز بدن است و یکیازمهمترینسرطانهاییاست کهجامعهبشریباآن درگیر میباشد(4). این بیماری در اثر تکثیر و تکامل ناقص گویچههای سفیدخونو پیشسازهای آن در خون و مغز استخوانایجاد میشود.در بیماری لوسمی، مغز استخوان به صورت غیر عادی، مقدار بسیار زیادی سلول خونی تولید میکند. این سلولها با سلولهایخون طبیعی متفاوت هستند و درست عمل نمیکنند. در نتیجه، تولید سلولهای سفید خون طبیعی را متوقف کرده و توانایی فرد را در مقابله بابیماریها از بین میبرند. سلولهای لوسمی بر تولید سایر انواع سلولهای خونی که از مغز استخوان تولید میشوند مانند گلبولهای قرمز خون و پلاکتها نیز تاثیر میگذارند(4). لوسمی نیز خود بر اساس طیف، شدت و سرعت پیشرفت روند بیماری به حاد و مزمن و نیز بر اساس نوع گلبول سفید درگیر، به لنفوئیدی و میلوئیدی تقسیم میشود(5، 4). 1- لوسمی میلوژنیک حاد(AML = Acute Myeloid Leukemia) سلولهای مغز استخوان یا میلوسیتها را تحث تاثیر قرار میدهد و روندی حاد دارد. در این بیماری، مغز استخوان، میلوبلاستها، گلبولهای قرمز یا پلاکتهای غیر طبیعی میسازد. 2- لوسمی میلوژنیک مزمن(CML = Chronic Myeloid Leukemia) سلولهای مغز استخوان یا میلوسیتها را تحت تاثیر قرار میدهد و روندی مزمن دارد. 3- لوسمی لنفوسیتیک حاد (ALL = Acute Lymphoblastic Leukemia) سلولهای لنفاوی یا لنفوسیتها را تحت تاثیر قرار میدهد و روندی حاد دارد(6). 4- لوسمی لنفوسیتیک مزمن(CLL = Chronic Lymphocytic Leukemia) سلولهای لنفاوی یا لنفوسیتها را تحث تاثیر قرار میدهد و روندی مزمن دارد. بـسیاری از مطالعـههـا رونـد بـدخیمـی لـوسمی را به ناهنجاریهای ژنتیکی نسبت میدهند و مطالعههایزیادی پیرامونکشفعواملمولکولیدرگیردراینبیماری صورتگرفتهاست(8 ،7).یکیازحوزههای جدیددانش درکشفبیانژنهادرحالتبیماری،استفادهازتکنولوژی ریز آرایه(میکرواری)است که یکتصویر کلیازمیزانبیان ژنراارایهمیدهد(8). تکنولوژیریز آرایه کهروشیبسیار قدرتمنداست، امکانبررسیهم زمان بسیاریازفعلو انفعالاتزیستیرافراهممیکند و انتظار میرود با تحلیلآماریتغییرات بیانهزارانژنبهطورهم زمان، بتوان ژنهای مؤثر در سرطان راشناساییودرزمینهدرمان اینبیماریگامهایمهمی برداشت(15-9). این تکنولوژی در دو زمینه ژنومیکس(مطالعهمجموعهژنهایموجودزنده) و پروتئومیکس(مطالعهمجموعه پروتئینهایموجود زنده) کاربردهایوسیعیدارد(8). در روش ریز آرایه هرتوالی ژنیشناختهشدهموردنظربهعنوانیک پروب(Probe) روی یک آرایه (Array) شیشهای یا نایلونی چاپ میشود.mRNA از بافتیانمونهخونبارنگهای فلورسنتعلامتگذاریمیشودوپروبهابرروییک آرایه هیبرید میشود. بهطورکلیبرایتهیه آرایه DNA بایدطبقمراحلزیرعمل کرد: نمونهگیری،خالصسازی نمونه،جداسازی mRNAها، انجامرونویسیمعکوسو تهیه cDNA، متصل کردن cDNAبهرنگهایفلوئورسنت، ریختن محلول بر رویسطحریزآرایه کهازقبلتوسط توالیهایژنموردنظرپوشیده شده است، انجام هیبریداسیونمیان DNA ها و توالیهایسطحریز آرایه، شستشو، بررسیوپردازش نتایج(16، 7). مهمترین کاربردهای ریز آرایه عبارتند از؛ بررسیبیانژنوتغییرات آندراثر عواملیمانند درمان، عوامل بیماریزا، آسیب سلول، هیبریدسازیمقایسهایژنوم، تعیینمحتوایژنوم موجوداتزنده،مقایسهآنهابایکدیگر، شناساییچند شکلیهایتکنوکلئوتیدی، تشخیصبیماری و طبقهبندی سرطان(17).ابعادبالا،تعدادنسبتاً کم نمونهها و تغییرپذیریذاتیدرفرآیندهای آزمایشگاهیو بیولوژیکی باعثایجادمشکلاتیدرآنالیزدادههایریزآرایه شدهاست، ازاین رو،اولینگاممهمدرآنالیزدادههای ریز آرایه، کاهش تعدادژنهایابهعبارتیانتخابژنهای متمایزکنندهاست و انجام این فرآیندها بدون کمک آنالیز آماری و روشهای هوشمند تحلیل اطلاعات ممکن نیست(18). الگوریتمهای مختلف داده کاوی و یادگیری ماشین (Machine learning) میتوانند در خوشهبندی و دستهبندی ژنها مورد استفاده قرار گیرند و این روشها کمک مؤثری درتصمیمگیریدرموردتشخیصبیماریهاوشیوهدرمان، ارایه میدهند(4). به کمک پیشرفتهای فناوری در بیوانفورماتیک و روشهایمولکولی،دادههایزیادی به دستآمده کهدرشناختزودرسبیماریسرطان کمک خواهد کرد. هم چنین غربالگریبهموقعبرایبعضیاز سرطانها، کمکمؤثریدرتشخیصزودرس آنمینماید (2). مطالعههای متعددی توسط محققان بر روی مجموعه دادههای بیان ژن لوسمی با روشهای مختلف انجام گرفته است(21-19).با توجه به این که گرفتنتصمیممناسب برای درمان انواع لوسمی ازمهمترینفعالیتهابعد از تشخیصنوع سرطاناست، هدف از انجام این مقاله، تشخیص لوسمی میلوژنیک و لنفوسیتیکحاد با استفاده از انتخاب ژن دادههای ریز آرایه و الگوریتمهای داده کاوی بود.
مواد و روشها مطالعهحاضر توصیفی وداده محوراست وپایهاصلیآنداده کاویوبررسیدادههای بیان ژنلوسمی میلوژنیکو لنفوسیتیک حاد میباشد که با استفاده از فناوری ریز آرایه به وجود آمده است. روشهایمختلفیبرایپیادهسازیو اجرایپروژههایداده کاویوجوددارد. در این مطالعه، مدلی جهت تشخیص لوسمی میلوژنیکو لنفوسیتیک حاد بر اساس متدولوژیCRISP ارائه شده که شامل فازهای شناخت سیستم، شناخت دادهها، آمادهسازی دادهها، مدلسازی، ارزیابی و توسعه میباشد. در ادامه، مراحلمدل پیشنهادی شرحدادهمیشوند.
شناخت سیستم: در مرحله شناختسیستم، اهدافسیستم موردنظر بررسی و مشخص میگردند. رشد گسترده لوسمی در جهان نیاز به سیستمی برای تشخیص آن را ضروری میسازد. یکی از دقیقترین روشها برای کشف و پیشبینی بیماری لوسمی، استفاده از DNA افراد و اطلاعات ژنتیکی آنها میباشد. تکنولوژی ریز آرایه، ابزاری برای بررسی بیان هزاران ژن در حداقل زمان ممکن است. هدف سیستم پیشنهادی، تشخیص هوشمند انواع لوسمی حاد با استفاده از مجموعه دادههای ریز آرایه و روشهای داده کاوی است.
شناختدادهها: مرحله شناخت دادهها شاملجمعآوریدادههایاولیه، توصیفدادهها و بازرسیوبررسیدادههااست. در این مطالعه از دادههای بیان 7129 ژن مربوط به 72 بیمار مبتلا به لوسمی میلوژنیک و لنفوسیتیک حاد استفاده شد که با کمک فناوری ریز آرایه به دست آمد و توسط گلوب و همکاران ارایه گردیده است(7). هر بیمار با بر چسب لوسمی میلوژنیک حاد یا لوسمی لنفوسیتیک حاد(ALL) مشخص گردید که نشاندهنده نوع لوسمی در وی بود. از 72 بیمار مذکور، 47 بیمار مبتلا به لوسمی لنفوسیتیکحاد و 25 بیمار مبتلا به لوسمی میلوژنیکحاد بودند. برای ارزیابی کارآییو مقایسه الگوریتمهای داده کاوی باید دادهها به دو دسته آزمون و آزمایشی تقسیم شوند و تمام الگوریتمها با مجموعه آموزشی یکسانی آموزش داده شده و با مجموعه آزمون یکسانی مورد آزمایش قرار گیرند. دادههای بیان ژن مورد استفاده در این مطالعه قبلاً به دو دسته دادههای آموزشی و دادههای آزمون تقسیم شدند. دادههای آموزشی، بیان ژن 38 بیمار( شامل 27 بیمار مبتلا به لوسمی لنفوسیتیک حاد و 11 بیمار مبتلا به لوسمی میلوژنیک حاد) و دادههای آزمون بیان ژن 34 بیمار( شامل 20 بیمار مبتلا به لوسمی لنفوسیتیکحاد و 14 بیمار مبتلا به لوسمی میلوژنیکحاد) را مشخص نمودند.
آمادهسازی دادهها: مرحله آمادهسازی دادههاجهتبهبود کیفیتدادههای واقعیبرایداده کاویلازماست و شامل انتخاب، پاکسازی، تبدیل دادهها و نرمالسازی دادهها است. انتخاب، تبدیل و تغییر شکل ویژگیها، مهمترین موضوعاتی هستند که کیفیت یک راه حل داده کاوی را تعیین میکنند. در دادههای به دست آمده توسط فناوری ریز آرایه که مربوط به بیان هزاران ژن هستند، یکی از مهمترین موضوعات، کاهش و انتخاب ژنها است. مسئله انتخاب ژندرواقع شناساییوانتخابیکزیر مجموعه مفیدازژنها استکهحداکثرتوانرادر پیشگوییلوسمی میلوژنیکیا لوسمی لنفوسیتیکحادداراباشند. در مدل پیشنهادی این مطالعه برای انتخاب ژنها از روشهای انتخاب ویژگی زیر استفاده گردید. 1- انتخاب ژنها با استفاده از روش انتخاب ویژگی مبتنی بر ضریب همبستگی(Correlation Coefficient) دادهها با داده تصمیمگیری(برچسب کلاس) 2- انتخاب ژنها با استفاده از روش انتخاب ویژگی بهره اطلاعاتی (Information Gain) 3- انتخاب ژنهابا استفاده از روش انتخاب ویژگی نسبت بهره (Gain Ratio) 4- انتخاب ژنها با استفاده از روش انتخاب ویژگی امتیاز Fisher (Fisher Score) در مدل پیشنهادی با استفاده از روشهای فوق به رتبهبندی ژنها پرداخته و ژنهای مهم با بالاترین رتبه انتخاب و ژنهای دارای رتبه پایین حذف میشوند. معیار انتخاب زیر مجموعه ژنها در مدل پیشنهادی مطابق رابطه زیر تعریف میشود:
در این رابطه [S1, S2,…, Sd] بردار مرتب شده رتبهبندی ژنها به صورت نزولی است. از بردار مرتب شده رتبه ژنها زیر مجموعهای از ژنها شامل kژن انتخاب میشوند بـه طوری که جمع رتبههـای آنهـا (C)، درصد جمع رتبههای تمام ژنها باشد. در این مطالعه، سه مقدار 01/0، 02/0 و 03/0 برای پارامتر C در نظرگرفته شدند.
مدلسازی: درمرحله مدلسازیبااستفادهاز الگوریتمهایمختلف داده کاوی،بهمدلسازی دادهها و پیدا کردن مدل بهینه پرداخته شد. برای مدلسازی از نرمفزار Matlab R2013a و ابزار دادهکاوی Weka استفاده میشود و روشهای جداکننده خطی، ماشین بردار پشتیبان (SVM-linear)، k نزدیکترین همسایه، بیزینساده، شبکهی بیزین، نزدیکترین میانگین، رگرسیون لجستیک، شبکهی عصبی پرسپترون چند لایه و درخت تصمیم J48 برای مدلسازی دادهها به کار میروند. در ادامه روشهای استفاده شده برای مدلسازی دادهها شرح داده میشوند: - روش جداکننده خطی: روش جداکننده خطی فرض میکند که نمونههای یک کلاس به صورت خطی از نمونههای کلاس دیگر جداپذیرند. جدا بودن خطی نمونه های یک کلاس بدین معناست که بتوان با استفاده از یک رابطه خطی، نمونههای یک کلاس را از نمونههای کلاس دیگر جدا نمود. - روش ماشین بردار پشتیبان (SVM): این روش با ساخت یک ابرسطح (که عبارت است از یک معادله خطی)، سعی دارد بهترین ابرسطحی را پیدا کند که با حداکثر فاصله ، دادههای مربوط به دو کلاس را از هم تفکیک کند. - روش k نزدیکترین همسایه (KNN): این روش یک روش دستهبندی است که تصمیمگیری در مورد این که یـک نمونـه جدید در کــدام کلاس قرار گیرد با بررسی تعدادی (k) از شبیهترین نمونهها یا همسایهها انجام میشود. این روش برای یافتن شباهت بین نمونهها نیاز به یک معیار فاصله نظیر فاصله اقلیدسی یا فاصله منهتن دارد. - روش بیزین ساده: این روش مبتنی بر قانون بیزین است و فرض میکند ویژگیها از هم مستقل هستند. در روش بیزین ساده تنها نیاز است تا واریانس ویژگیها به ازای هر کلاس محاسبه شود و نیازی به محاسبه ماتریس کوواریانس نیست. - شبکه بیزین: شبکه بیزین یک گراف جهتدارغیر حلقوی است که از گرهها برای نمایشژنهاو از کمانها برای نمایش روابط احتمالی مابین ژنها استفاده میکند. در این شبکـه، xi یـک ژن اسـت و گرههای والد این ژن بـا Parent(xi) نشـان داده میشونـد و توزیعاحتمالتوأم مجموعهایازژنهامحاسبه میگردد. - روش نزدیکترین میانگین: این روش بر اساس قانون بیزین است و فرض میکند ویژگیها از هم مستقل هستند. روش نزدیکترین میانگین فرض میکند که واریانس همه کلاسها و هم چنین احتمالهای پیشین تمام کلاسها مساوی هستند و نمونه جدید را به کلاسی با نزدیکترین میانگین اختصاص میدهد. - رگرسیونلجستیک: رگرسیونلجستیکیکیازمدلهای خطی تعمیمیافتهاست که برایتحلیلرابطهیکیاچندمتغیر اسمی برمتغیرپاسخرستهایبهکارمیرود. رگرسیون لجستیک، شبیه رگرسیون خطی است با این تفاوت که نحوه محاسبه ضرایب در این دو روش یکسان نمیباشد. رگرسیون لجستیک، به جای حداقل کردن مجذور خطاها، احتمال وقوع یک واقعه را حداکثر میکند. رگرسیون لجستیک از آمارههای کای اسکوئر(c2) و والد استفاده میکند. - شبکههایعصبی پرسپترون چند لایه: شبکههایعصبی مصنوعیازیکسریلایههاشاملاجزایسادهایبه نام نرونتشکیلشدهاند که هماهنگباهمبرایحل مسائل به کارمیروند. شبکههای عصبی پرسپترون از چند لایه شامللایه ورودی،لایههایپنهانولایهخروجیتشکیل شدهاست. در شبکه عصبی پرسپترون چند لایه، هر نرون در هر لایه به تمام نرونهای لایه قبل متصل است. لایه ورودی،یک لایهانتقالدهندهو لایهخروجیشاملمقادیر پیشبینی شده به وسیلهشبکهاست ولایههایپنهان کهازنرونهای پردازشگرتشکیلشدهاند ومحلپردازشدادهها هستند. - درخت تصمیم J48 : درخت تصمیم،ساختاریشبیهبه فلوچارتداردکهبالاترینگره،ریشهدرختاست و گرههای برگ، دستهها یا توزیع دستهها را نشان میدهند. درخت تصمیم بامرتب کردننمونههادردرختازگره ریشهبهسمتگرههایبرگ آنها را دستهبندیمیکند. الگوریتم J48 ، درخت تصمیم C4.5 است که توسط نرمافزار Weka ارایه میشود و از مفهوم آنتروپی اطلاعات استفاده میکند. ارزیابی: دراینمرحلهبهارزیابینتایج حاصلازمدلسازی با استفاده از شاخصهای دقت، حساسیت و اختصاصیت پرداخته میشود. میزاندقتیکروشدستهبندیبرروی مجموعهدادههای آزمون،درصدمشاهداتیازمجموعه آزمون است کهبهدرستیتوسطمدلمورداستفاده دستهبندیشده است. حساسیتعبارت است از میزانی برای مشخصکردن توانایی سیستم در تشخیص و دستهبندی بیماران مبتلا به لوسمی میلوژنیکحاد که سیستم آنها را به صورت صحیح دستهبندی مینماید. اختصاصیت عبارت است از میزانی برای مشخصکردن توانایی سیستم در تشخیص و دستهبندی بیماران مبتلا به لوسمی لنفوستیکحاد که سیستم آنها را به صورت صحیح لوسمی لنفوستیکحاد تشخیص میدهد.
توسعه: در مرحله توسعه، با توجه به نتایج به دست آمده در مرحله ارزیابی، مدلی که دارای عملکرد مناسبی است برای دستهبندی دادهها به کار میرود.
یافتهها در این مطالعه، سه مقدار 01/0، 02/0 و 03/0 برای پارامتر C در نظر گرفته میشوند. تعداد ژنهای انتخاب شده توسط روشهای انتخاب ژن با مقادیر مختلف پارامتر C در جدول 1 نشان داده شده است. همان گونه که در جدول 1 مشخص شده است، تعداد ژنها با استفاده از تمام روشهای انتخاب ژن به طور قابل توجهی کاهش یافته است. پس از انتخاب ژنها، روشهای جداکننده خطی، نزدیکترین میانگین، ماشینبردار پشتیبان (SVM-Linear) ، روش k نزدیکترین همسایه، شبکه بیـزین، بیزیـن ساده، رگرسیـون لجستیـک، شبکـه عصبـی پرسپترون چند لایه و درخت تصمیم J48 بر روی این دادهها اجرا میگردند. در روشهای دستهبندی ذکر شده، بهترین ژنها در هریک از روشهای انتخاب ژن (مقدار بهینه پارامتر C) با استفاده از روش اعتبارسنجی متقاطع با ده تکرار بر روی مجموعه آموزشی به دست آمده است. مقدار بهینه پارامتر k در روش k نزدیکترین همسایه نیز با استفاده از روش اعتبارسنجی متقاطع با ده تکرار بر روی مجموعه آموزشی به دست آمد. سپس آزمایشها را با استفاده از ژنهای انتخاب شده بر روی مجموعه دادههای آزمون انجام دادیم. نتایج بررسی روشهای گوناگون دستهبندی با استفاده از شاخصهای دقت، حساسیت و اختصاصیت با استفاده از روش انتخاب ژن ضریب همبستگی بر روی مجموعه دادههای آزمون نشان داده شد (جدول 2). همان گونه که در جدول 2 مشاهده میشود، روش ماشینبردار پشتیبان با استفاده از 77 ژن انتخاب شده توسط ضریب همبستگی، دارای عملکرد بهتری در مقایسه با سایر روشها است و با دقت بالایی قادر به تشخیص لوسمی میلوژنیکو لنفوسیتیک حاد است. روش درخت تصمیم J48 و رگرسیون لجستیک، دارای عملکرد نسبتاً ضعیفی در دستهبندی انواع لوسمی حاد میباشد.
جدول 1: تعداد ژنهای انتخاب شده توسط روشهای انتخاب ژن
روش انتخاب ژن
مقدار پارامتر C
تعداد ژنهای انتخاب شده
ضریب همبستگی
01/0
38
بهره اطلاعاتی
01/0
45
نسبت بهره
01/0
39
امتیاز Fisher
01/0
10
ضریب همبستگی
02/0
77
بهره اطلاعاتی
02/0
87
نسبت بهره
02/0
86
امتیاز Fisher
02/0
24
ضریب همبستگی
03/0
116
بهره اطلاعاتی
03/0
133
نسبت بهره
03/0
123
امتیاز Fisher
03/0
41
جدول 2: نتایج عملکرد روشهای دستهبندی بر روی ژنهای انتخاب شده توسط ضریب همبستگی
نام روش
تعداد ژن
دقت
حساسیت
اختصاصیت
جداکننده خطی
77
71/64%
20%
33/83%
نزدیکترین میانگین
38
24/38%
100%
50/12%
ماشینبردار پشتیبان
77
06/97%
100%
83/95%
k نزدیکترین همسایه (1= k)
38
12/94%
100%
67/91%
شبکیه بیزین
38
24/38%
100%
50/12%
بیزین ساده
38
12/94%
100%
67/91%
رگرسیون لجستیک
116
47/26%
50%
67/16%
شبکه عصبی پرسپترون
38
18/91%
100%
50/87%
درخت تصمیم 48 J
116
47/26%
90%
0%
جدول 3: نتایج عملکرد روشهای دستهبندی بر روی ژنهای انتخاب شده توسط بهره اطلاعاتی
نام روش
تعداد ژن
دقت
حساسیت
اختصاصیت
جداکننده خطی
87
53/73%
20%
83/95%
نزدیکترین میانگین
45
06/97%
100%
83/95%
ماشینبردار پشتیبان
87
100%
100%
100%
k نزدیکترین همسایه(5 = k)
45
06/97%
100%
83/95%
شبکه بیزین
45
24/38%
100%
50/12%
بیزین ساده
45
06/97%
100%
83/95%
رگرسیون لجستیک
45
12/44%
100%
83/20%
شبکه عصبی پرسپترون
133
100%
100%
100%
درخت تصمیم 48J
45
35/32%
100%
17/4%
جدول 4: نتایج عملکرد روشهای دستهبندی بر روی ژنهای انتخاب شده توسط نسبت بهره
نام روش
تعداد ژن
دقت
حساسیت
اختصاصیت
جداکننده خطی
39
59/20%
40%
50/12%
نزدیکترین میانگین
39
100%
100%
100%
ماشینبردار پشتیبان
39
100%
100%
100%
k نزدیکترین همسایه(5= k)
39
100%
100%
100%
شبکه بیزین
86
06/97%
100%
83/95%
بیزین ساده
39
100%
100%
100%
رگرسیون لجستیک
39
06/97%
100%
83/95%
شبکه عصبی پرسپترون
39
100%
100%
100%
درخت تصمیم 48 J
39
35/32%
100%
17/4%
جدول 5: نتایج عملکرد روشهای دستهبندی بر روی ژنهای انتخاب شده توسط نسبت امتیاز Fisher
نام روش
تعداد ژن
دقت
حساسیت
اختصاصیت
جداکننده خطی
10
12/44%
90%
25%
نزدیکترین میانگین
24
12/94%
100%
67/91%
ماشینبردار پشتیبان
41
06/97%
100%
83/95%
k نزدیکترین همسایه(1= k)
41
12/94%
100%
67/91%
شبکه بیزین
41
18/41%
100%
67/16%
بیزین ساده
24
06/97%
100%
83/95%
رگرسیون لجستیک
24
18/41%
100%
67/16%
شبکه عصبی پرسپترون
10
18/41%
100%
67/16%
درخت تصمیم 48 J
10
35/32%
100%
17/4%
نتایج عملکرد روشهای دستهبندی گوناگون بر روی ژنهای انتخاب شده، توسط روش بهره اطلاعاتی بر روی مجموعه دادههای آزمون به دست آمد(جدول 3). نتایج جدول 3 نشان میدهد که روشهای ماشینبردار پشتیبان و شبکه عصبی پرسپترون چند لایه با استفاده از ژنهای مناسب انتخاب شده، توسط بهره اطلاعاتی با دقت 100٪ قادر به تشخیص انواع لوسمی حاد هستند. روشهای نزدیکترین میانگین، k نزدیکترین همسایه و بیزین ساده نیز دارای عملکرد خوبی در تشخیص لوسمی میلوژنیکو لنفوسیتیک حاد هستند. جدول 4، نتایج عملکرد روشهای دستهبندی گوناگون بر روی ژنهـای انتخـاب شـده توسـط روش نسبـت بهره بر روی مجموعه دادههای آزمون را نشان میدهد. همان گونه که در جدول 4 نشان داده شده است، روشهای نزدیکترین میانگین، ماشینبردار پشتیبان، k نزدیکترین همسایه، بیزین ساده و شبکه عصبی پرسپترون چند لایه با استفاده از ژنهای انتخاب شده توسط نسبت بهره با دقت 100٪ قادر به تشخیص لوسمی میلوژنیکو لنفوسیتیک حاد هستند. روشهای شبکه بیزین و رگرسیون لجستیک نیز دارای عملکرد خوبی در تشخیص انواع لوسمی حاد هستند. نتایج عملکرد روشهای دستهبندی گوناگون با استفاده از روش انتخاب ژن بر روی مجموعه دادههای آزمون نشان داده شد(جدول 5).
جدول 6: 39 ژن انتخاب شده توسط معیار نسبت بهره
توصیف ژن
شماره الحاق ژن
توصیف ژن
شماره الحاق ژن
ADM Adrenomedullin
D14874_at
CYSTATIN A
D88422_at
SNRPN Small nuclear ribonucleoprotein polypeptide N
SNRPN Small nuclear ribonucleoprotein polypeptide N
J04615_at
CPM Carboxypeptidase M
J04970_at
نتایج حاصل از ارزیابی روشهای گوناگون دستهبندی نشان میدهد که روش ماشینبردار پشتیبان با استفاده از تمام روشهای انتخاب ژن، دارای عملکرد بالایی در تشخیص انواع لوسمی حاد است. روشهای نزدیکترین میانگین، ماشین بردار پشتیبان، k نزدیکترین همسایه، بیزین ساده و شبکه عصبی پرسپترون چند لایه با استفاده از 39 ژن انتخاب شده توسط نسبت بهره با دقت 100٪ ، قادر به تشخیص لوسمی میلوژنیک و لنفوسیتیک حاد هستند(جدول 6). هم چنین روش ماشینبردار پشتیبان با استفاده از 87 ژن انتخاب شده توسط بهره اطلاعاتی و روش شبکه عصبی پرسپترون چند لایه با استفاده از 133 ژن انتخاب شده، توسط بهره اطلاعاتی با دقت 100٪ قادر به تشخیص لوسمی میلوژنیک و لنفوسیتیک حاد هستند. روشهای درخت تصمیم 48J و جداکننده خطی با استفاده از ژنهای انتخاب شده توسط تمام روشهای انتخاب ژن دارای عملکرد ضعیفی هستند.
بحث در این مطالعه دادههای حاصل از ریزآرایه بیماری لوسمی توسط روشهای نزدیکترین میانگین، ماشینبردار پشتیبان، k نزدیکترین همسایه، بیزین ساده و شبکه عصبی پرسپترون چند لایه با استفاده از 39 ژن انتخاب شده توسط نسبت بهره با دقت 100% قادر به تشخیص لوسمی میلوژنیک و لنفوسیتیک حاد بودند. هم چنین روش ماشینبردار پشتیبان با استفاده از 87 ژن انتخاب شده توسط بهره اطلاعاتی و روش شبکه عصبی پرسپترون چند لایه با استفاده از 133 ژن انتخاب شده توسط بهره اطلاعاتی با دقت 100% قادر به تشخیص لوسمی میلوژنیک و لنفوسیتیک حاد هستند. لین و چن با روش شبکه عصبی BP به بررسی مجموعه دادههای بیان ژن لوسمی در سال 2011 پرداختند و با دقت 83/95% قادر به تشخیص انواع
سرطان بودند. همین محققان در سال 2011 با روش MTSVSL قادر به تشخیص انواع لوسمی با دقت 67/96% شدند(21). کای و همکاران در سال 2014 برای تشخیص لوسمی از روش I-RELIEF-NB استفاده کردند و با دقت 67/91% قادر به تشخیص انواع لوسمی شدند. این محققان در همان سال با استفاده از روش RELIEF-KNN برای تشخیص سرطان لوسمی به دقت 4/94% دست یافتند(22). هنگ و همکاران در سال 2012 با استفاده از روش BMSF-NB به تشخیص انواع لوسمی پرداختند و با دقت 25/96% قادر به تشخیص لوسمی ALL از AML شدند. همین محققان از روش Gene SrF-NB استفاده نمودند و قادر به تشخیص لوسمی با دقت 58/94% شدند(23). آزادی و همکاران در مطالعه با استفاده از دادههای بیان ژن و آزمایشهای آماری، ژنهای مسئول لوسمی حاد را تشخیص دادند و در پایان مطالعه گزارش کردند که شناخت این ژنها جهت درمان و حتی پیشگیری از آن میتواند بسیار مهم و حایز اهمیت باشد. هم چنین این محققان در مطالعه خود گزارش کردند با اطلاع از نحوه بیان این ژنها در افراد مبتلا، پزشکان قادر خواهند بود که با تجویز داروها و روشهای درمانی مناسب، میزان بیان آنها را کنترل نمایند و باعث کاهش مرگ و میر ناشی از این نوع بیماریها شود(24).
نتیجهگیری نتایج این مطالعه نشان داد که انتخاب ژنها و الگوریتمهای داده کاوی قادر به تشخیص انواع لوسمی با دقت بسیار بالایی هستند، بنابراین با استفاده از تکنولوژی ریزآرایه و الگوریتمهای دادهکاوی با تشخیص دقیق انواع لوسمی، میتوان تصمیمات مناسبی در مورد نحوه تشخیص و درمان بیماران گرفت.
Sheikhpour R, Aghaseram M, Sheikhpour R. Diagnosis of acute myeloid and lymphoblastic leukemia using gene selection of microarray data and data mining algorithm. Sci J Iran Blood Transfus Organ 2016; 12 (4) :347-357 URL: http://bloodjournal.ir/article-1-930-fa.html
شیخ پور راضیه، آقاصرام مهدی، شیخپور رباب. تشخیص لوسمی لنفوسیتی و میلوئیدی حاد با استفاده از انتخاب ژن دادههای ریزآرایه و الگوریتمهای داده کاوی. فصلنامه پژوهشی خون. 1394; 12 (4) :347-357